Hello all,
We are having a critical issue in our production Openfire cluster, where room occupant list does not correctly sync when a node is started/restarted. We observe this issue in** Openfire clusters hosted in both CentOS / RHL and OSX**. We have not tested this under Windows as we don’t use any Windows systems at our work place. Here are the details:
Environment
Scenario
-
Start the 1st Openfire node (Node-1) in the cluster.
-
Login a few users, and make these users join a room (in our tests, the room is called BEACH).
-
Start the 2nd Openfire node (Node-2).
-
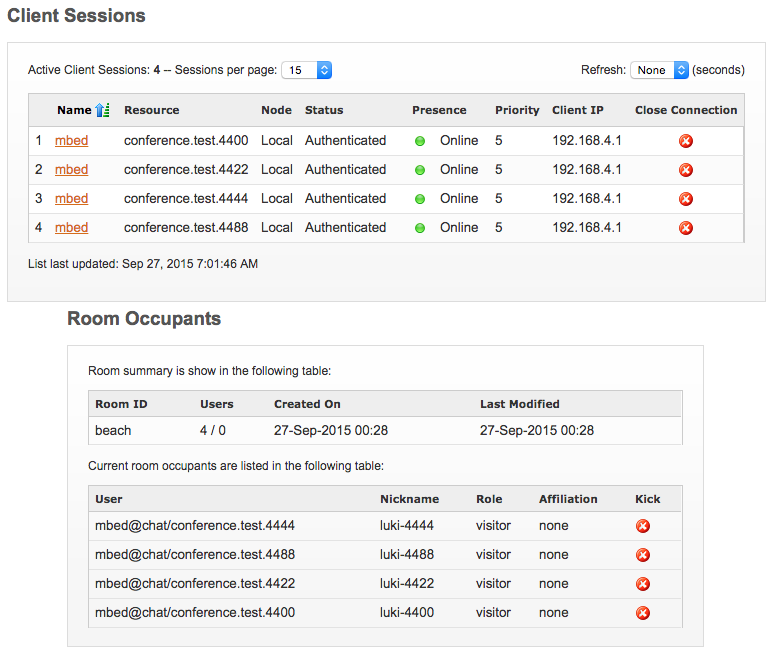
Once the nodes have completed syncing, compare the “Client Sessions” page of Node-1 with that of Node-2. As expected, they should both show the same information.
-
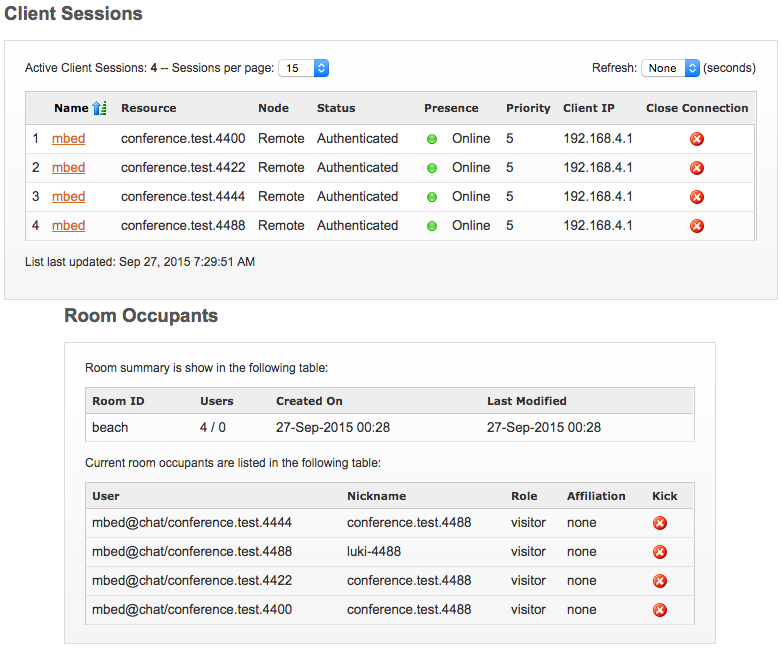
Now compare the room occupant lists of the BEACH room (or whatever the room where users joined) of the two nodes. In Node-2, nicknames of some or all of the room occupants are incorrect. Their real nicknames have been replaced with resource IDs of other occupants in the same room.
-
In Node-2, try to kick a room occupants who has an incorrect nickname. Openfire throws an error saying the user cannot be kicked.
-
Terminate the all user sessions (through the admin console of Node-1 or Node-2), after which room occupants with the incorrect nicknames still exist in Node-2. So, in short these are ghost users.
Please also refer to attached screenshots.
node1.png: Node-1 sessions page and room occupants page for BEACH room.
node2.png: Node-2 sessions page and room occupants page for BEACH room. Incorrect nicknames of some occupants can be seen here.
I can reproduce these ghost users every time I run the above scenario. I use a simple JavaScript program to create user sessions via websockets. However, we have also seen this issue when using sockets and BOSH. I have attached the JS test program here. To run, create a user called “mbed” with the password “mirror”, and also create a room called “beach” under conference.net.
I have also attached our Openfire configuration (openfire.xml) cluster configuration (cluster.xml) files.
I have also tested the above scenario with Openfire 3.10/Hazelcast plug 2.0.0/Hazelcast 3.4.6 and get the same results. So, this appears to be an issue either in the plugin or Openfire.
I would greatly appreciate if someone could help us resolve this issue, or let us know if this is a bug in Openfire. Please let me know if additional information is required. I am happy to share as much information as possible to nail this nasty issue.
Many thanks and kind regards,
Luki
websocket-local.html.zip (1193 Bytes)
cluster.xml.zip (4025 Bytes)
openfire.xml.zip (1209 Bytes)
Hello again,
After a few weeks of trying various things and debugging the code for some days, we may have found the bug in the Openfire code that is causing this issue.
While debugging, we noticed that getNickname() in the OccupantAddedEvent class returns an incorrect nickname. We modified the code in this method at line 72 as follows (tagged version v3.10.0):
Openfire/OccupantAddedEvent.java at v3.10.0 · igniterealtime/Openfire · GitHub
Old: return presence.getTo().getResource().trim();
New: return presence.getFrom().getResource().trim();
We have done some initial testing with a build having this change in our local cluster, and we NO LONGER observe any ghost users described in the original post. We are continuing with our testing to ensure nothing else has broken as a result of this change.
In the meantime, we would be grateful if someone could provide feedback if the above change is correct and does not break functionality. We will initiate a pull request if the fix is acceptable.
We look forward to hearing from you.
Thank you and regards,
Luki
Hi Luki,
Thanks for your efforts on this. Hopefully @Tom Evans can comment on this suggested change.
daryl
Hi Luki -
Yes, it looks like your proposed patch would be a suitable fix for the problem. I don’t anticipate any undesirable side effects given the current implementation. Feel free to submit a PR via Github - thanks for your contribution.
Regards,
Tom
Created OF-954 to track this patch.
Hi Tom / Daryl,
Thanks for your responses and feedback. Tom also thanks for creating the JIRA ticket. During the course of our testing, we have identified another scenario that leads to orphaned room occupants (i.e. ghost users). I will provide more details in the above JIRA ticket once we have more clarity. We believe that this new issue has been masked by the one I posted here. More details to follow
Cheers,
Luki
Hi @Tom Evans / @Daryl Herzmann,
The new issue we found can be reproduced easily as follows. Make sure you patch Openfire with the earlier fix proposed above before carrying out this test and we assume a 2-node cluster.
-
Start only Node-1 of the cluster.
-
Login a user to his node and make this user join a room.
-
Start Node-2 of the cluster. After a couple of seconds, the user session and room presence should be replicated in Node-2.
-
Stop Node-1. Since the user was connected to Node-1, this should kill the user session and remove the corresponding room presence. However, only the session is killed in Node-2, and the room presence remains. This orphaned room occupant cannot be kicked.
If you have an idea what could be causing this bug, please let us know. Your help will be much appreciated. In the meantime we will continue our investigation.
Cheers,
Luki
Hi Tom / Daryl,
We noticed that the reason why the room occupant is not removed in the above scenario is because the following validate() method is not called:
Openfire/RemoteSession.java at v3.10.0 · igniterealtime/Openfire · GitHub
However, the above method is invoked in a different thread if we place a breakpoint at the beginning of the following memberRemoved() method:
Openfire/ClusterListener.java at v3.10.0 · igniterealtime/Openfire · GitHub
The validate() method is invoked couple of seconds after memberRemoved() is invoked, provided that memberRemoved() is halted at the start. So it appears that memberRemoved() does something that stops the validate() method from being called, in turn stopping appropriate clean up of the chat room.
An ideas?
Cheers,
Luki
Hi Tom / Daryl,
After days of debugging, we are still unable to figure out what’s causing ghost room occupants when a node goes down. Therefore, we focused on cleaning up any orphaned room occupants, if any, associated the defunct node. We added a method to end of the leftCluster(nodeId) method in RoutingTableImple to do this clean up:
Openfire/RoutingTableImpl.java at v3.10.2 · igniterealtime/Openfire · GitHub
The new method is:
private void removeOrphanedRoomOccupants(byte[] nodeID) {
Log.info("Removing orphaned occupants associated with defunct node: " + StringUtils.getString(nodeID));
XMPPServer instance = XMPPServer.getInstance();
List allServices = instance.getMultiUserChatManager().getMultiUserChatServices();
for (MultiUserChatService service : allServices) {
for (MUCRoom mucRoom : service.getChatRooms()) {
Collection occupants = mucRoom.getOccupants();
for (MUCRole mucRole : occupants) {
if (mucRole.getNodeID().equals(nodeID)) {
mucRoom.leaveRoom(mucRole);
}
}
}
}
}
We know that this not fix for the issue, but rather a fail safe mechanism in the event the room occupants are not cleaned at the end of leftCluster().
Kindly let us know your thoughts on the above fix.
Cheers,Luki
Hi Luki -
This logic would be better located (and slightly simpler) in the MultiUserChatManager class, which also implements the ClusterEventListener interface. Otherwise I think this approach is fine as a cleanup step after a cluster node drops out.
Cheers,
Tom
Hi Tom,
Thanks for your feedback. As per your suggestion, we have placed the clean up logic within the leftCluster(byte[] nodeID) of the MultiUserChatManager class. Our initial tests looks promising as we no longer see orphaned room occupants / ghost users when a cluster node goes down. Once we are satisfied, I will submit a pull request.
Cheers,
Luki
Hi Tom,
I don’t have permissions to do push to Openfire repo, so here are the changes we made to the MultiUserChatManager class. You may relate this commit to the OF-954 issue as this is part of the fix, in addition to the earlier one we proposed.
import org.jivesoftware.util.StringUtils;
public void leftCluster(byte[] nodeID) {
// Remove all room occupants linked to the defunct node as their sessions are cleaned out earlier
Log.info("Removing orphaned occupants associated with defunct node: " + StringUtils.getString(nodeID));
for (MultiUserChatService service : getMultiUserChatServices()) {
for (MUCRoom mucRoom : service.getChatRooms()) {
for (MUCRole mucRole : mucRoom.getOccupants()) {
if (mucRole.getNodeID().equals(nodeID)) {
mucRoom.leaveRoom(mucRole);
}
}
}
}
}
Cheers,
Luki
Hi @Tom Evans
Were you all able to merge the above fix added to the MultiUserChatManager into the main code base of Openfire? If not we would like it to be merged so we can have this fix in future version of Openfire.
Cheers,
Luki
Hi @Daryl Herzmann / @Tom Evans,
Would you be able to give an update on this issue? This is very critical to our business, and therefore, if the above fix is not the correct approach, could you tell if this has been fixed (or could be fixed) through some other means? Having said that, we have a patched version of Openfire 3.10.2 with the above fix that works well in our setup.
Cheers,
Luki
Hi Luki -
Yes, it seems your additional patch was never applied. I have reopened the JIRA item to track this further contribution, which we will fold into the next incremental release.
Thanks,
Tom
Hi Tom,
Thank for your reply and we are very happy to hear that the fix has been merged into the code base. We are looking forward to seeing this fix included in the next incremental release.
Cheers,
Luki